What’s Ilya Sutskever’s superintelligence supposed to do for us anyway?
Feed the hungry? Solve world peace? We could do that all ourselves.
This past week I’ve been reading about llya Sutskever and his company Safe Superintelligence Inc., SSI.
In 2022, while Sutskever was still chief scientist at OpenAI, he remarked that advanced AI models might have some rudimentary form of consciousness: “it may be that today’s large neural networks are slightly conscious”.
Let’s dive into the word “neural”.
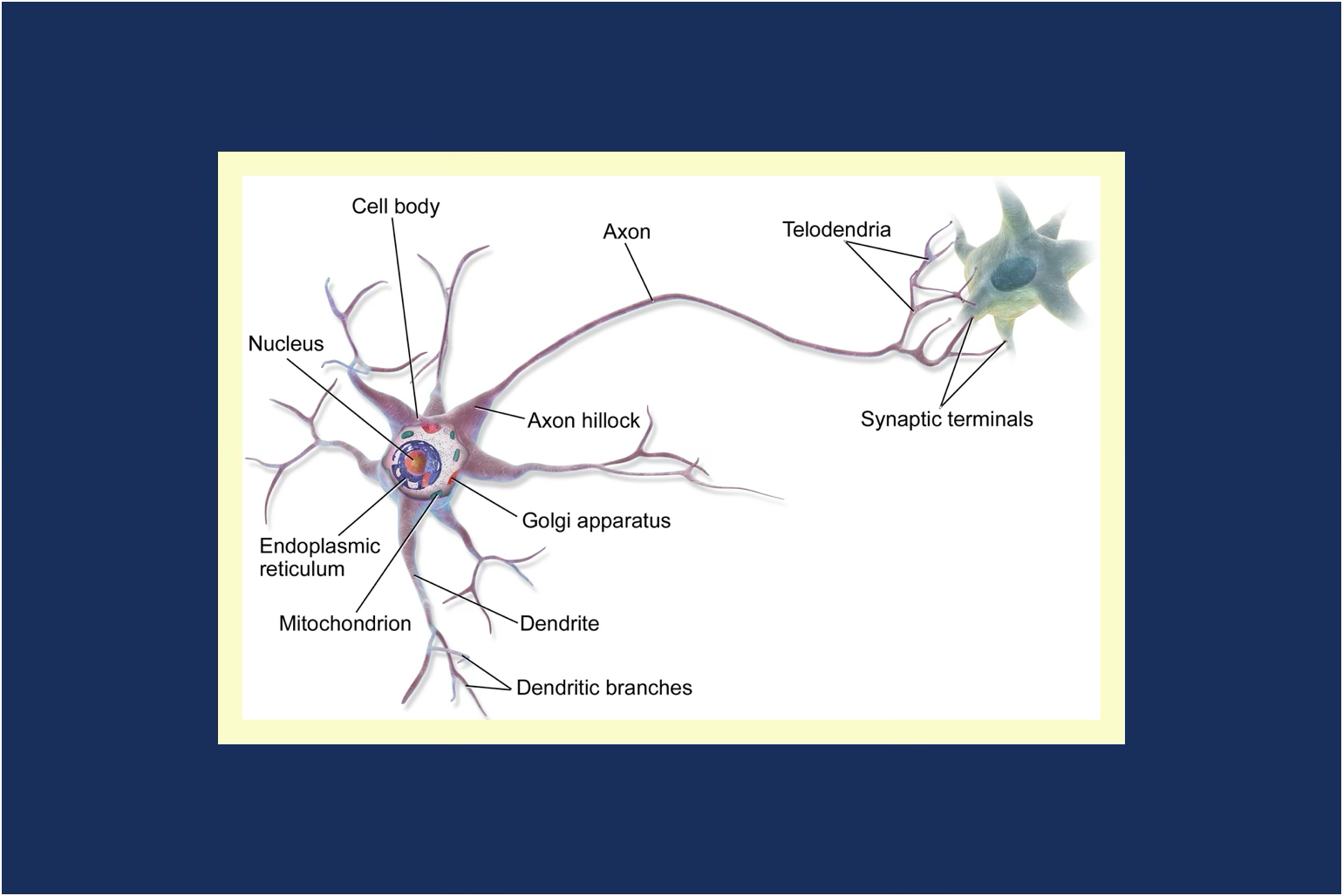
How ‘Neural’ Networks Got Their Name
A neurone is a basic element of the nervous system of all animals. We might think of them as residing exclusively in our brain, in fact they propagate throughout our bodies. They send information in the form of minute electrical and chemical pulses. In humans, some are more than a metre long.
Sutskever’s career started with his collaboration on the image recognition system AlexNet, which took work done by the Japanese scientist Kunihiko Fukushima in the 60s to the next level of complexity.
Researchers like Fukushima have taken biological neurones as inspiration for their studies into creating artificial neurones since the field started during the Second World War.
Is Consciousness Emergent?
Why would Sutskever think that artificial neural networks could become conscious? Could he think that consciousness is an emergent property, just like the theory that human or animal consciousness is emergent?
Emergence as a concept is widely accepted in science. Temperature emerges from the collective motion of molecules, even though individual molecules don’t have temperature. It’s a property that arises from sufficiently complex systems.
Astrophysicist Sara Imari Walker is a prominent proponent of the idea that consciousness could be a fundamental property of matter,
The Problem with ‘Slightly Conscious’ AI
There’s no agreed-upon definition or test for consciousness, let alone in non-biological systems. But if artificial neural networks could become conscious, even slightly, it raises urgent questions about the ethics of AI. Such as whether we might inadvertently create systems capable of suffering, deserving rights.
Or want to rule the world.
‘Safe’ Superintelligence: A Noble Goal
Hence the word “safe” in the name of Sutskever’s company.
The goal is to build the world’s first safe superintelligent AI system. Superintelligence that surpasses human intelligence in all domains but is aligned with human values and incapable of causing harm.
Where “in all domains” means an AI that outperforms humans in reasoning, creativity, and problem-solving across all fields
And safe?
The AI must understand and prioritise well-being. Should be aligned to care about "sentient life", which would include us, our cat, but also any emergent sentience in non-biological entities.
The importance of safety should override any drive towards intermediate product releases and profit-taking. In fact, the problem of safety should be solved before the technological problem of superintelligence itself.
Why New Solutions Won’t Fix Old Problems
But when it arrives, Sutskever is convinced that superintelligence could solve humanity’s biggest challenges: climate change, disease, poverty.
I think that’s a noble cause. Apparently, so do others. SSI has attracted billions in investments.
But I’m a bit of a skeptic. Not that it couldn’t come up with new solutions, but if we could come to consensus about actually executing them.
Weak results from COP30 and the antagonistic approach to climate change we’re seeing from the United States and other large countries show that politics, corruption, and money bests science every time.
Betting Billions on a Decades-Long Maybe
Generally, venture capital tends toward time frames of 8 to 10 years. Does Sutskever’s time frame align?
Absolutely not. The alignment and safety problems alone could take decades to resolve. Nevertheless, as a co-founder of OpenAI and a pioneer in deep learning, Sutskever is seen as one of the few people capable of delivering on such an ambitious goal. Investors are betting on his track record and vision. The risk of not investing in such a high-stakes endeavor is seen as greater than the risk of a long wait.
The Glaring Hole in Sutskever’s Plan: No Politics
When I started this post, I thought that Sutskever’s approach was of a naive scientist who follows theories instead of politics. I still do. His strategy for SSI is technically sound, but there’s no political plan.
Nations and corporations are already in a race for AI dominance, with little regard for safety or alignment. China, the U.S., and private actors like Meta, Google, and OpenAI are pouring billions into AI, with speed and competitive advantage dominating ethics.
Without a strategy to influence global AI governance, by which I mean treaties, regulations, or alliances, its "safe" superintelligence could become irrelevant.
The One Silver Lining
But for politics, we ourselves could solve all problems Sutskever claims superintelligence could solve. It’s not about new solutions, it’s about execution of the old ones.
If there is one positive point to be gleaned from this, then it’s the apparent willingness of venture capital to forgo quick wins. To settle in for the long haul of investing in technology that might take decades to come to fruit.